I am currently testing a software that does work with several CUDA GPUs.
The code contains supports both Linux and Windows.
What has been baffling me is the contrary results between Linux and Win.
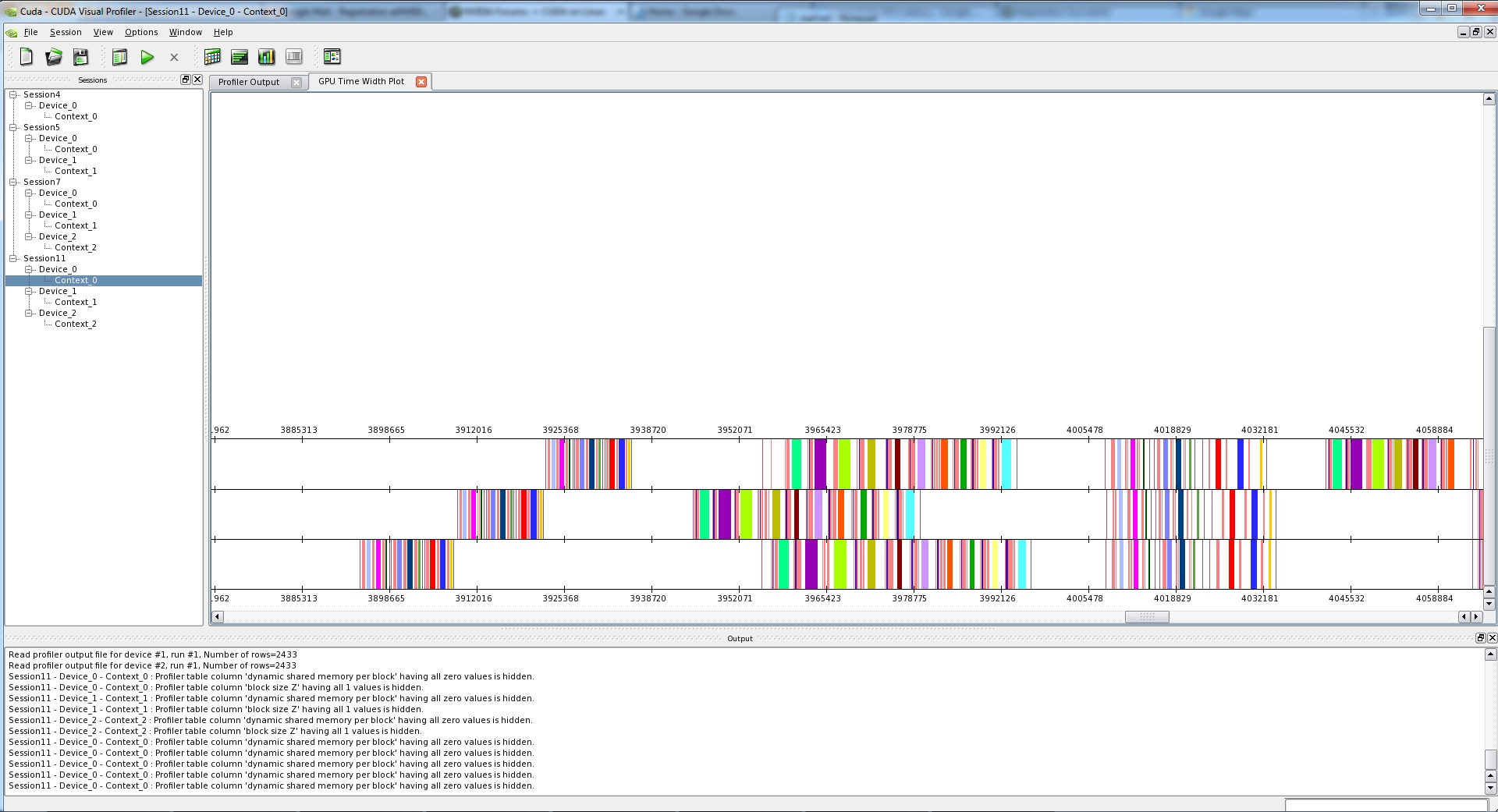
I ran Cuda-Profiler on both systems (uploaded in the attachments).
We can see that in Windows it runs just as expected (the second CUDA is slower because it’s a slower card):
each thread calls are nicely packed together and thus increases the overall efficiency as expected.
However, in Linux, the GPUs seem to have a hard time running threads in parallel:
They are executed in serial, such as the first three blocks
They are called in parallel but the are spread out and overall calculation time of the threads are about the same as in serial, such as the six blocks.
Has anyone else experienced a similar problem? If so, is there anything I could do about this?
I have a multi GPU code working on linux. We used the profiler in command line to reconstruct the time line and everything was fine including mem copy and compute kernel overlapping. After that i used the visual profiler and notice exactly your problem: the launch are serialized and the profiler say that is no memory transfer and kernel overlapping. At this point i suppose that is a bug in the visual profiler.
I made i try with 4.1RC2 and that solve my kernel and memory transfer overlapping issue: now the profiler shows overlapped transfers and kernel as expected.
By the way i have another issue: “Event/metric collect failed” kernels behaving differently between runs …
I will open another post for that.