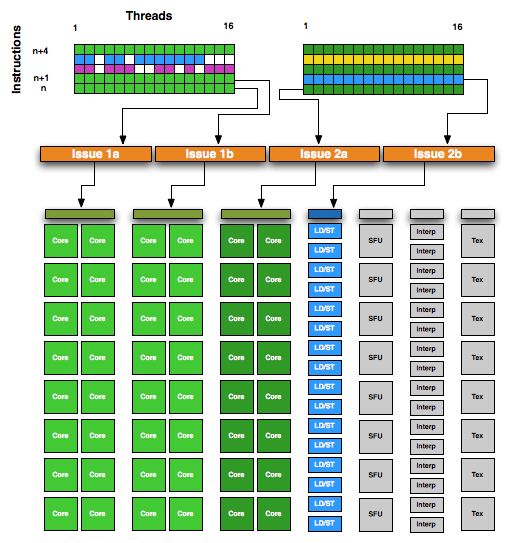
I am finding the explanation of DP in these reviews very confusing. In GF100, the warp scheduler could issue two warp instructions at a time, each warp going to a different group of 16 CUDA cores inside the same multiprocessor. (Hence the throughput of 2 instructions every 2 clocks) In the case of a double precision instruction, one warp would require all 32 CUDA cores, presumably because two CUDA cores can team up to perform a DP operation. This drops the throughput of DP to 1/2 that of SP (1 DP instruction every 2 clocks), at least at the hardware level. GeForce cards are further capped to perform DP at a level of 1 DP instruction per 8 clocks.
So now the confusion with GF104 is the extra set of 16 CUDA cores per multiprocessor. As I understood the garbled explanations, this extra set of cores cannot assist in DP instruction execution, but the other two sets of 16 cores work the same as GF100. This would mean that a multiprocessor still can only complete a DP instruction for a warp in 8 clocks, despite having 48 CUDA cores available. This leads me to believe the 7 SMs on the GTX 460 have a peak DP rate of 75.6 GFLOPS (7 multiprocessors * 1.35 GHz / 8 clocks/warp * 32 threads in a warp * 2 operations in MAD) unless NVIDIA removed the artificial cap present on GeForce GF100s.
However, this is very unclear. Someone needs to just do some microbenchmarking on a GTX 460 and tell us the answer.
I’ve upgraded to CUDA 3.1 and it hasn’t improved my bandwidthtest results at all. However, it does seem to be possible to achieve higher bandwidths than this in some kernels so I haven’t yet given up all hope. Sadly my code is still running much slower on a GTX 460 than it does on a GTX 260. My code has been hand-optimised using decuda/cudasm. This optimisation is of course not being used on the GTX 460. The main thing the optimisation does is reduce the register usage from 23 to 16. This takes occupancy up from 0.5 to 1.0 and as a result the total global memory bandwidth usage of my kernel goes up from about 52GB/s to about 80GB/s. If I could achieve the same sort of improvement on the GTX 460 then things would be looking better but the extra registers mean I’m already at an occupancy of 0.667 so there’s presumably not so much to be gained and to make matters worse there is no decuda/cudasm for Fermi. What can I do?
I’m wondering if their won’t be a Tesla GF104 remix (GTX460, but with all CUDA cores having FP64 units)
Since one of the issues with Tesla’s have been their power consumption.
That SP number definitely looks low to me too, so I wonder what benchmark CUDA-Z runs to get it… Given that the DP number matches the calculation so well, I wonder if the SP benchmark is partially memory bound on the GTX 460. (Although I’m amazed your 9600 GSO is hitting 500 GFLOPS with only 96 cores at 1.35 GHz…)
Mostly likely not, since they also removed the ECC logic from this GPU design, making it unsuitable for Tesla. (Now I’d be willing to bet that someone is probably merging good ideas from the GF104 into a future Tesla chip, but part of the reason this chip has better power consumption and price is because they removed and rebalanced features for a consumer market.)
Yes they are. I get similar results with gflops.c posted by Simon Green a long time ago. I cannot believe you get 500 GFlops with a 9600 GSO. I am not suprised by the bandwidth of the GTX-460. The NVIDIA website says 80 GB/s for the 768 MB version that I have and I get 50. I had a similar result for GTX-260, supposedly 112 GB/s and getting about 80 to 90 GB/s. I have a separate post with a question on the number of cores per MP: were deviceQuery to believe the GTX-460 would have 32 cores per MP (GF-100) and not the supposed 48 cores per MP (GF-104).
SHOC looks neat! Although I wonder how that peak GFLOPS number is calculated. Given that all the benchmarks seem to run slower on OpenCL (good to know!), I see no reason why peak GFLOPS should be high for OpenCL unless that number is calculated based on some device properties rather than measured with some microbenchmark.
Imaging that you haven’t read any marketing papers, just having the GTX460.
It reports some weird clock rate (810Mhz) but it’s OK as GTX470 doing the same. It reports 7xSMs and compute caps 2.1. Running some benchmarks and getting 302 Giops it translates into 224SP@1.348Ghz speed for shaders. Now, 224 SP * 1.350 (let’s round it) / 8 (DPFP rate) * 2 (MAD) = 75.6 theoretical Gflops for DPFP. Matches perfectly. Weirdly, SPFP benchmark doesn’t looks good, instead of 604.8 GFlops it’s only 523. You’re assume that probably there some issues with drivers/benchmark. And your final assumption is that GTX460 is simply cut in half GF100, 7xSMs * 32 = 224 CUDA cores.
After this you’re getting some marketing papers and see “336 SP” there. Your reaction? :P
So is the 523 Gflops Single precision coming from only 2/3rd of SPs being used due to the compiler not knowing about the superscaler nature of the 460?
Or because CUDA-Z doesn’t consider instruction level parallelism in its benchmark.
These 523GFlops looks pretty weird – at worst case scenario (== no ILP) GF104 should use 32 out of 48 CUDA cores per SM and shows 605GFlops with GTX460, at best case scenario 48/48 = 907GFlops. Why performance dropped below 605GFlops is really interesting question.
It’s not a surprise that for synthetic benchmarks it’s hard to find not-depending instructions (and so got any ILP) as usually these benchmarks looks like
repeat NNN times
MAD A,A,B
So getting higher than 605GFlops is very unlikely here. However, there no performance drops for integer calculations compared with SPFP. Weird again.
Looks like to utilize GF104 fully (for some applications, cryptography applies here 100%) we’ll need to vectorize code as it required for ATI GPUs already. But instead of int4(float4) int2(float2) should be enough. However, as register count stays the same as for GF100, register pressure for GF104 will be much higher which may leads to another performance drops. Interesting situation.
{kind=link}
![http://images.anandtech.com/reviews/video/...460/GF140sm.png[/url]](http://images.anandtech.com/reviews/video/...460/GF140sm.png%5B/url%5D){kind=link}